
다음 예제들과 인덱스는 ELK stack이 구축되어 있다는 가정하에, 키바나에서 제공하는 샘플데이터를 이용합니다.
키바나 홈 -> Get started by adding integrations

엘라스틱서치에서 집계는 데이터를 그룹핑하고 통계값을 얻는 기능으로 SQL의 GROUP BY와 통계 함수를 포함하는 개념입니다. 이를테면 데이터를 날짜별로 묶거나 특정 카테고리별로 묶어 그룹별 통계를 내는 방식입니다.
집계가 중요한 이유는 키바나의 주 기능인 데이터 시각화와 대시보드는 대부분 집계 기능을 기반으로 동작하며, 집계를 제대로 이해할수록 키바나라는 툴을 더 잘 사용할 수 있습니다.
집계의 요청 / 응답 형태
집계를 위한 특별한 API가 제공되는 것은 아니며, search API의 요청 본문에 aggs 파라미터를 이용하여 쿼리 결과에 대한 집계를 생성할 수 있습니다.
GET examplw_index/_search
{
"aggs": {
"my_aggs": {
"AGG_TYPE": {
...
}
}
}
}aggs는 집계 요청을 하겠다는 의미입니다.
my_aggs는 사용자가 지정하는 집계 이름입니다.
agg_type은 집계 타입을 의미합니다.
다음은 위 요청에 대한 응답 결과입니다.

aggregations은 이 응답메시지가 집계 요청에 대한 결과임을 알려줍니다.
my_aggs는 집계 이름으로 사용자가 지정한 이름입니다.
value는 실제 집계 결과입니다.
집계는 크게 메트릭 집계와 버킷 집계라는 두 가지 타입의 집계가 있습니다.
메트릭집계는 통계나 계산에 사용되며, 버킷 집계는 도큐먼트를 그룹핑하는데 사용됩니다.
메트릭 집계
메트릭 집계는 필드의 최소/최대/합계/평균/중간값 같은 통계 결과를 보여줍니다.
메트릭 집계 종류
- avg | 필드의 평균값
- min | 필드의 최솟값
- max | 필드의 최댓값
- sum | 필드의 총합
- percentiles | 필드의 백분윗값
- stats | 필드의 min, max, sum, avg, count를 한번에 봄
- cardinality | 필드의 유니크한 값 개수
- geo-centroid | 필드 내부의 위치 정보의 중심점
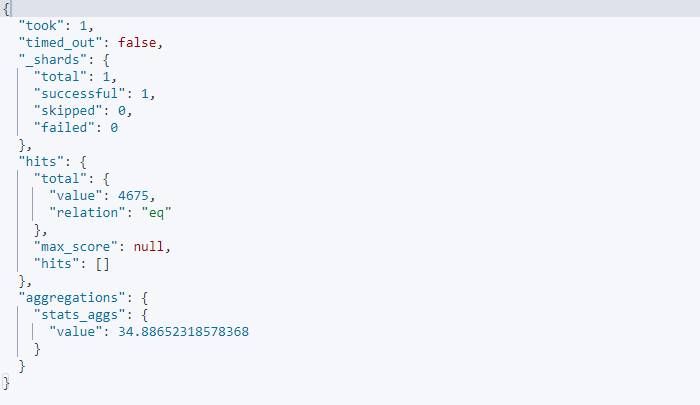
평균값을 구하는 집계 요청
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"stats_aggs": {
"avg": {
"field": "products.base_price"
}
}
}
}
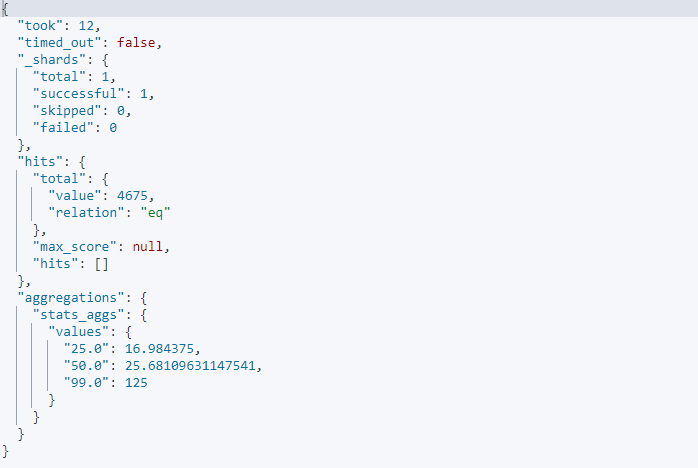
백분위를 구하는 집계 요청
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"stats_aggs": {
"percentiles": {
"field": "products.base_price",
"percents": [
25,
50,
99
]
}
}
}
}
필드의 유니크한 값 개수 확인하기
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"cardi_aggs": {
"cardinality": {
"field": "day_of_week",
"precision_threshold": 100
}
}
}
}
"precision_threshold" 파라미터는 정확도 수치라고 이해할 수 있습니다. 값이 클수록 정확도가 올라가는 대신 시스템 리소스를 많이 소모하기 때문에 적절한 값을 사용해야 합니다.
이때 사용되는 알고리즘은 HyperLogLog++ 알고리즘으로 엘라스틱서치와 같이 대용량 데이터베이스에서 유용한 알고리즘입니다.
확률적 자료구조를 이용한 추정 - 유일한 원소 개수(Cardinality) 추정과 HyperLogLog
용어 집계 요청
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"cardi_aggs": {
"terms": {
"field": "day_of_week"
}
}
}
}
필드 내부의 유니크한 값을 표현해주면서 유니크한 각 값의 도큐먼트 개수도 보여줍니다.
검색 결과 내에서의 집계
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"query": {
"term": {
"day_of_week": "Monday"
}
},
"aggs": {
"query_aggs": {
"sum": {
"field": "products.base_price"
}
}
}
}
버킷 집계
버킷 집계는 특정 기준에 맞춰서 도큐먼트를 그룹핑하는 역할을 합니다. 여기서 버킷은 도큐먼트가 분할되는 단위로 나뉜 각 그룹을 의미힙니다.
버킷집계종류
- histogram | 숫자 타입 필드를 일정 간격으로 분류
- date_histogram | 날짜/시간 타입 필드를 일정 날짜/시간 간격으로 분류
- range | 숫자 타입 필드를 사용자가 지정하는 범위 간격으로 분류
- date_range | 날짜/시간 타입 필드를 사용자가 지정하는 날짜/시간 간격으로 분류
- terms | 필드에 많이 나타나는 용어들을 기준으로 분류
- significant_terms | terms 버킷과 유사하나, 모든 값을 대상으로 하지 않고 인덱스 내 전체 문서 대비 현재 검색 조건에서 통계적으로 유의미한 값들을 기준으로 분류
- filters | 각 그룹에 포함시킬 문서의 조건을 직접 지정
히스토그램 집계
히스토그램 집계는 숫자 타입 필드를 일정 간격 기준으로 구분해주는 집계입니다. 버킷의 범위를 동일하게 지정할 수 밖에 없다는 단점이 있습니다.
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"histogram_aggs": {
"histogram": {
"field": "products.base_price",
"interval": 100
}
}
}
}
products.base_price 필드의 값을 100단위로 구분했는데, key가 0은 필드값이 0-99사이의 값임을 의미합니다.
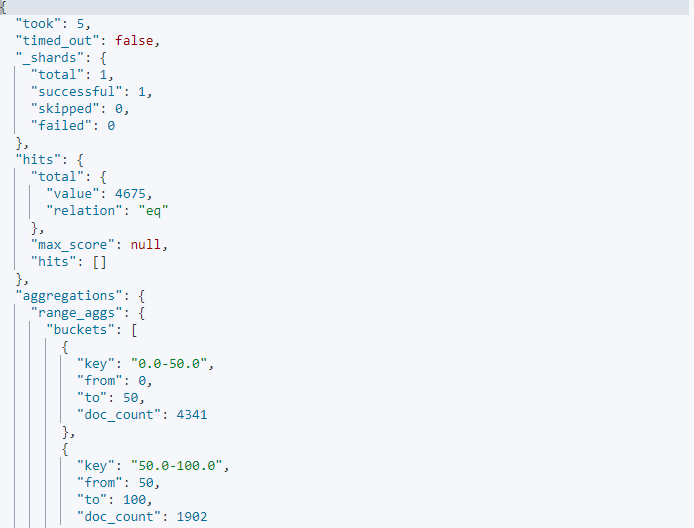
범위 집계
범위 집게를 이용하면 각 버킷의 범위를 사용자가 직접 설정할 수 있습니다. 특정 구간에 데이터가 몰려 있거나 데이터 편차가 큰 경우에 사용하면 좋습니다.
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"range_aggs": {
"range": {
"field": "products.base_price",
"ranges": [
{"from": 0, "to": 50},
{"from": 50, "to": 100},
{"from": 100, "to": 150},
{"from": 150, "to": 200}
]
}
}
}
}
용어 집계
용어집계는 필드의 유니크한 값을 기준으로 버킷을 나눌 때 사용합니다.
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"term_aggs": {
"terms": {
"field": "day_of_week",
"size": 6
}
}
}
}
용어 집계가 부정확도를 표시하는 이유는 분산 시스템의 집계 과정에서 발생하는 잠재적인 오류 가능성 때문입니다. 분산 시스템에서는 데이터를 여러 노드에서 분산하고 취합하는 과정에서 오류가 발생할 수 있습니다.
예를 들어 요일 데이터가 샤드1, 샤드2에 분산되어 저장되어있다고 해봅시다. size가 6이라고 했을 때 샤드 1에서는 일요일을 빼버리고 샤드2에서는 토요일을 빼버려 집계하고 이걸 취합해서 다시 집계하게 되면 정확한 값과 다른 결과가 나오게 됩니다.
따라서 용어 집계의 정확성을 높이기 위해서는 고속처리를 위한 리소스가 필요합니다.
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"term_aggs": {
"terms": {
"field": "day_of_week",
"size": 6,
"show_term_doc_count_error": true
}
}
}
}
위와같이 용어 집계를 요청할 때 show_term_doc_count_error 파라미터를 추가합니다.
집계의 조합
메트릭 집계로 특정 필드들의 통계를 구할 수 있고 버킷 집계를 이용해 도큐먼트를 그룹핑할 수 있다는 것을 알았습니다. 관계형 데이터베이스에서 GROUP BY로 그룹핑한 다음 통계함수를 사용하는 것 처럼 메트릭 집계와 버킷 집계를 조합하여 다양한 그룹별 통계를 계산할 수 있습니다.
버킷 집계와 메트릭 집계를 동시에 요청해보겠습니다.
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"term_aggs": {
"terms": {
"field": "day_of_week",
"size": 5
},
"aggs": {
"avg_aggs": {
"avg": {
"field": "products.base_price"
}
}
}
}
}
}
버킷 집계 후 다수의 메트릭 집계 요청
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"term_aggs": {
"terms": {
"field": "day_of_week",
"size": 5
},
"aggs": {
"avg_aggs": {
"avg": {
"field": "products.base_price"
}
},
"sum_aggs":{
"sum": {
"field": "products.base_price"
}
}
}
}
}
}
버킷 집계 내부에서 2개의 메트릭 집계가 동작합니다. 먼저 용어 집계로 요일별로 상위 5개 버킷을 만든 뒤, 버킷내부에서 필드의 평균값과 총합을 구하는 두 번의 메트릭 집계를 각각 수행합니다.
서브 버킷 집계
서브 버킷은 버킷 안에서 다시 버킷 집계를 요청하는 집계입니다. 버킷 집계로 버킷을 생성한 다음 버킷 내부에서 다시 버킷 집계를 하는데 트리 구조를 생각하면 됩니다.
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"histogram_aggs": {
"histogram": {
"field": "products.base_price",
"interval": 100
},
"aggs": {
"term_aggs": {
"terms": {
"field": "day_of_week",
"size": 2
}
}
}
}
}
}
파이프라인 집계
파이프라인 집계는 이전 결과를 다음 단계에서 이용하는 파이프라인 개념을 차용합니다. 엘라스틱 파이프라인 집계는 이전 진계로 만들어진 결과를 입력으로 삼아 다시 집계하는 방식입니다. 이 과정에서는 부모 집계와 형제 집계라는 두 가지 유형이 있습니다. 부모집계는 기존 집계 내부에서 작성하고 형제 집계는 기존 집계 외부에서 새로 작성합니다.
자세한 내용과 집계 종류는 아래 문서를 확인해주세요.
8.4 파이프라인 - Pipeline Aggregations - Elastic 가이드북
Aggregation 중에는 다른 metrics aggregation의 결과를 새로운 입력으로 하는 pipeline aggregation이 있습니다. pipeline 에는 다른 버킷의 결과들을 다시 연산하는 min_bucket, max_bucket, avg_bucket, sum_bucket, stats_bucket
esbook.kimjmin.net
부모 집계
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"histogram_aggs": {
"histogram": {
"field": "products.base_price",
"interval": 100
},
"aggs": {
"sum_aggs": {
"sum": {
"field": "taxful_total_price"
}
},
"cum_sum":{
"cumulative_sum": {
"buckets_path": "sum_aggs"
}
}
}
}
}
}
형제 집계
GET kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"terms_aggs": {
"terms": {
"field": "day_of_week",
"size": 2
},
"aggs": {
"sum_aggs": {
"sum": {
"field": "products.base_price"
}
}
}
},
"sum_total_price": {
"sum_bucket": {
"buckets_path": "term_aggs>sum_aggs"
}
}
}
}
'개발 > ELK' 카테고리의 다른 글
| Elasticsearch 기본 (0) | 2023.05.17 |
|---|---|
| [Logstash] 로그스태시 파이프라인, 필터 (1) | 2023.04.11 |
| [Elasticsearch] 검색 쿼리 (1) | 2023.04.07 |
| [Elasticsearch] 벌크 데이터 bulk API (0) | 2023.03.27 |
| [Elasticsearch] CRUD - 데이터 입력, 조회, 삭제, 수정 (0) | 2023.03.27 |




댓글