
이 글에서 다루는 내용들은 ELK stack이 구축되어 있다는 가정하에 작성하였습니다.

로그스태시는 플러그인 기반의 오픈소스 데이터 처리 파이프라인 도구입니다. 다소 복잡하고 귀찮은 데이터 전처리 과정을 별도의 어플리케이션 작성 없이 비교적 간단한 설정만으로 수행할 수 있습니다.
로그스태시는 ELK stack에서 데이터를 수집 - 변환 - 저장 - 시각화 하는 서비스를 구성할 때 로그스태시는 데이터를 수집하거나 원하는 형태로 가공하는 역할을 합니다. 비츠를 포함한 여러 소스 파일을 입력으로 받을 수 있고 데이터를 수정/삭제/추가해 엘라스틱서치나 다른 시스템으로 데이터를 전송할 수 있습니다.

로그스태시에서 가장 중요한 부분은 파이프라인입니다.
파이프라인은 데이터를 입력받아 실시간으로 변경하고 이를 다른 시스템에 전달하는 역할을 하는 로그스태시의 핵심 기능입니다. 파이프라인은 입력, 필터, 출력이라는 세가지 구성요소로 이루어져있습니다.
입력은 소스로부터 데이터를 받아들이는 모듈, 필터는 입력으로 들어오는 데이터를 원하는 형태로 가공하는 모듈, 출력은 데이터를 외부로 전달하는 모듈입니다.
로그스태시는 JSON 형태로 데이터를 출력하는데, @version이나 @timestamp는 로그스태시가 만든 필드로 혹시 사용자가 만든 필드와 충돌이 날 것을 대비해 앞에 @기호가 붙어있습니다.
입력
파이프라인의 가장 앞부분에 위치하며 소스 원본으로부터 데이터를 입력받는 단계입니다.
다양한 입력 플로그인을 제공하는데 전체 입력 플러그인은 아래 문서를 확인해주세요.
Input plugins | Logstash Reference [8.7] | Elastic
www.elastic.co
아래는 파일 플러그인을 통한 입력입니다.
먼저 로그파일을 다음과 같이 임의로 만들어줍니다.
example.log
[2020-01-02 14:17] [ID1] 192.10.2.6 9500 [INFO] - connected.
[2020/01/02 14:19:25] [ID2] 218.25.32.70 1070 [warn] - busy server.
이후 로그스태시가 설치된 config 폴더의 logstash.conf 파일을 수정합니다.
logstash.conf
input {
file {
path => "/usr/share/logstash/mydata/example.log"
start_position => "beginning"
sincedb_path => "nul"
}
output {
stdout {}
}path는 log 파일이 있는 경로입니다.
start_position은 로그스태시가 새로운 파일을 인식했을 때 파일을 어디서부터 읽을 것인지에 대한 옵션으로 beginning과 end중 하나를 선택할 수 있습니다. beginning은 파일의 처음, end는 파일의 끝을 가리킵니다.
sincedb_path는 sincedb데이터베이스 파일이 대상 파일을 어디까지 읽었는지 기록합니다.
위 파일을 작성한 뒤 logstash를 실행합니다.

입력 플러그인 경로에 적힌 파일이 업데이트 될 때마다 출력 플러그인의 stdout에 의해 모니터에 위와 같은 로그들이 보일 것입니다.
화면을 보면 example.log 에 임의로 작성해놓은 2개의 로그가 로그스태시를 통해 처리되었습니다.
@version, sth, ost, timestamp 같은 필드는 위에서 언급한 부분으로 로그스태시에서 임의로 만든 필드이고
message 필드에 적힌 구문이 입력플러그인을 통해 들어온 로그입니다.
이 구문을 분석하여 의미있는데이터로 변환 하는것이 로그스태시의 가장 중요한 역할입니다.
필터
필터는 입력 플러그인이 받은 데이터를 의미있는 데이터로 구조화하는 역할을 합니다.
필수 구성요소는 아니지만 필터없는 파이프라인은 그 기능을 발휘할 수 없습니다.
자주 사용되는 필터 플러그인에 대해 다뤄보겠습니다. 전체 필터 플러그인은 아래 문서를 참고하세요.
Filter plugins | Logstash Reference [8.7] | Elastic
www.elastic.co
아래 예제에서 logstash.conf 파일의 input과 output은 수정하지 않고 filter를 추가합니다.
mutate를 이용한 문자열 자르기
mutate 플러그인에서 split 옵션을 이용한 문자열을 분리합니다.
logstash.conf
input {
file {
path => "/usr/share/logstash/mydata/example.log"
start_position => "beginning"
sincedb_path => "nul"
}
filter {
mutate {
split => { "message" => " " }
}
}
output {
stdout {}
}
mutate 플러그인은 필드를 변형하는 다양한 기능들을 제공하고 있습니다. split 옵션은 구분자를 기준으로 데이터를 자를 수 있습니다. 위에서는 message라는 필드를 공백기준 (" ")으로 문자를 분리합니다.
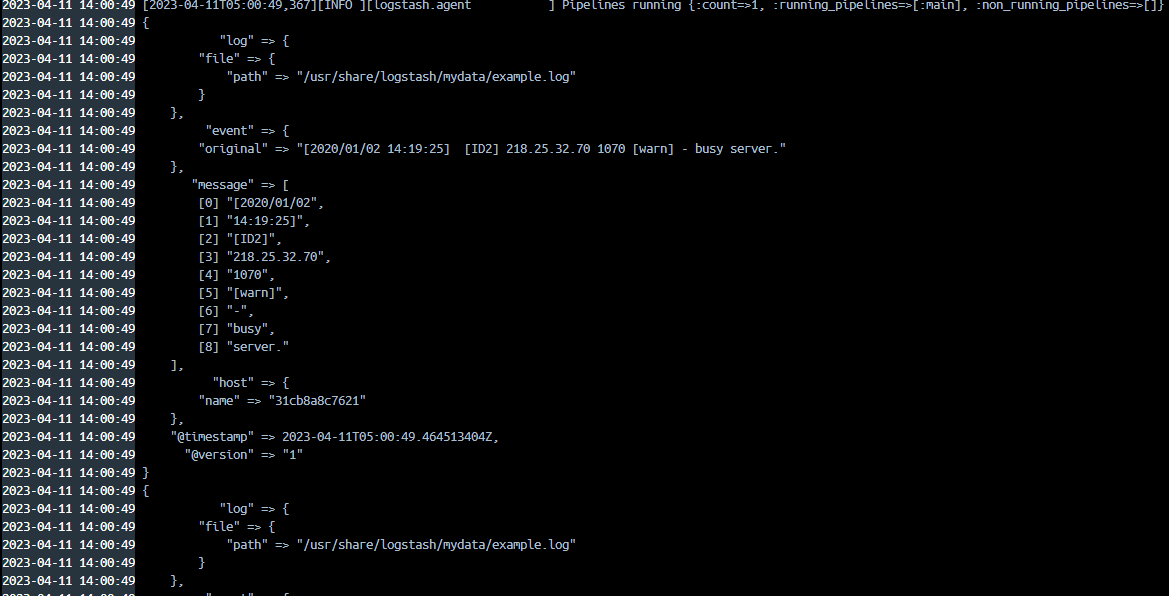
message 필드 문자열이 공백을 기준으로 구분되어 배열 형태의 데이터가 되었습니다.
mutate 옵션
- split | 쉼표 공백 같은 구분 문자를 기준으로 문자열을 배열로 나눔
- rename | 필드이름을 바꿈
- replace | 해당 필드값을 특정값으로 바꿈
- uppercase | 문자를 대문자로
- lowercase | 문자를 소문자로
- join | 배열을 쉼표같은 구분 문자로 연결해 하나의 문자열로 합
- gsub | 정규식이 일치하는 항목을 다른 문자열로 대체
- merge | 특정 필드를 다른 필드에 포함
- coerce | null인 필드값에 기본값을 넣음
- strip | 필드값의 좌우 공백 제거
mutate 플러그인에는 추가적인 옵션이 있는데 add_field 와 같은 옵션을 사용하면 새로운 필드를 만들거나 데이터를 넣을 수 있습니다.
- add_field | 새로운 필드 추가
- add_tag | 성공한 이벤트에 태그 추가
- enable_metric | 메트릭 로깅 활성화 또는 비활성화
- id | 플러그인의 아이디 설정
- remove_field | 필드 삭제
- remove_tag | 성공한 이벤트에 붙은 태그 제거
input {
file {
path => "/usr/share/logstash/mydata/example.log"
start_position => "beginning"
sincedb_path => "nul"
}
filter {
mutate {
split => { "message" => " " }
add_field => { "id" => "%{[message][2]}" }
remove_field => "message"
}
}
output {
stdout {}
}먼저 split에 의해 message 필드의 문자열이 공백을 기준으로 분리되었습니다. 다음으로 id 필드를 추가하고 필드값은 message[2]를 사용합니다.

dissect를 이용한 문자열 파싱
dissect 플러그인은 패턴을 이용해 문자열을 분석하고 주요 정보를 필드로 추출하는 기능을 수행합니다.
logstash.conf
...
filter {
dissect {
mapping => { "message" => "[%{timestamp}] [%{id}] %{ip} %{port} [%{level}] - %{message}." }
}
}
...dissect 플러그인의 mapping 옵션에 구분자 형태를 정의하고 필드를 구분합니다. %{필드명}으로 작성하면 중괄호 안의 필드명으로 새로운 필드가 만들어집니다.
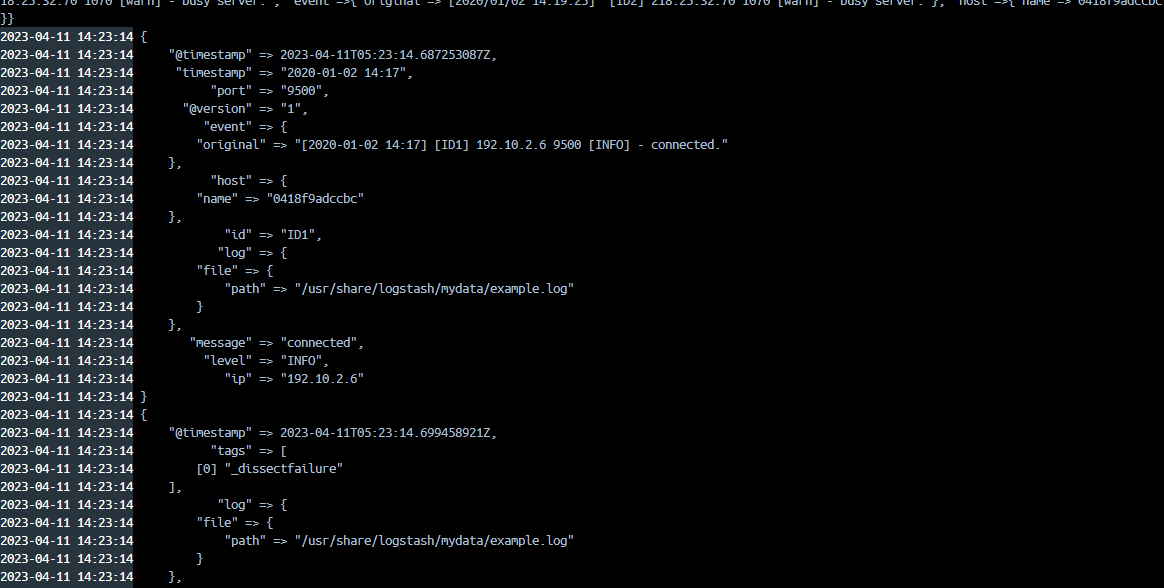
결과를 확인해 보면 각 구분자에 맞게 message 필드의 문자열이 배열로 저장됩니다.
하지만 두 번째 로그에서 문제가 발생합니다.
_dissectfailure는 dissect 필터 플러그인이 동작하지 않을 경우 발생합니다.
두번째 로그에 [timestamp]와 [id] 사이의 공백이 세칸이기 때문에 매핑에서 정해놓은 구분자가 아니기 때문에 오류가 발생한 것입니다. dissect 플러그인에서는 공백 한칸과 세칸을 다르게 인식합니다.
이를 해결하기 위해 매핑에 적용할 수 있는 몇가지 기호를 사용해보겠습니다.
logstash.conf
...
filter {
dissect {
mapping => { "message" => "[%{timestamp}]%{?->}[%{id}] %{ip} %{+ip} [%{?level}] - %{}." }
}
}
...
-> 기호는 공백을 무시합니다. 공백이 몇칸이든 하나의 공백으로 인식합니다.
%{?필드명} 혹은 %{}를 입력하면 그 필드명은 결과에 포함하지 않습니다.
%{+필드명}을 작성하면 여러 개의 필드를 하나의 필드로 합쳐서 표현합니다.

grok를 이용한 문자열 파싱
grok는 정규 표현식을 이용해 문자열을 파싱할 수 있습니다.
grok 패턴
- NUMBER | 십진수 인식
- SPACE | 스페이스, 탭 등 하나 이상의 공백 인식
- URI | URI 인식
- IP | IP 주소 인식
- SYSLOGBASE | 시스로그의 일반적인 포맷에서 타임스탬프, 중요도, 호스트, 프로세스 정보까지 메시지 외의 헤더 부분 인식
- TIMESTAMP_ISO08601 | ISO08601포맷의 타임스탬프 인식 (2020-02-02T12:00:00+09:00와 같은 형태)
- DATA | 이 패턴의 직전 패턴부터 다음 패턴 사이 인식
- GREEDYDATA | DATA타입과 동일하지만 표현식의 가장 뒤에 위치시킬경우 해당 위치부터 이벤트 끝까지 값으로 인식
logstash.conf
...
filter {
grok {
match => { "message" => "\[%TIMESTAMP_ISO8601:timestamp}\] [ ]*\[%{DATA:id}\] %{IP:ip} %{NUMBER:port:int} \[%{LOGLEVEL:level}\] \- %{DATA:msg}\."}
}
}
...
첫번째 로그는 원하는 형태로 필드가 구분되었지만 두번째 로그는 날짜/시간 데이터포맷이 맞지않아서 오류가 발생했습니다. 현재 제공하는 grok의 패턴으로는 0000/00/00의 패턴을 인식하지 못합니다.
따라서 사용자가 패턴을 지정해주어야 합니다.
대소문자 변경
mutate 플러그인의 uppercase 옵션을 이용해 소문자를 대문자로 변경합니다.
logstash.conf
...
filter {
dissect {
mapping => { "message" => "[%{?timestamp}]%{?->}[%{?id}] %{?ip} %{?port} [%{level}] - %{?msg}." }
}
mutate {
uppercase => ["level"]
}
}
...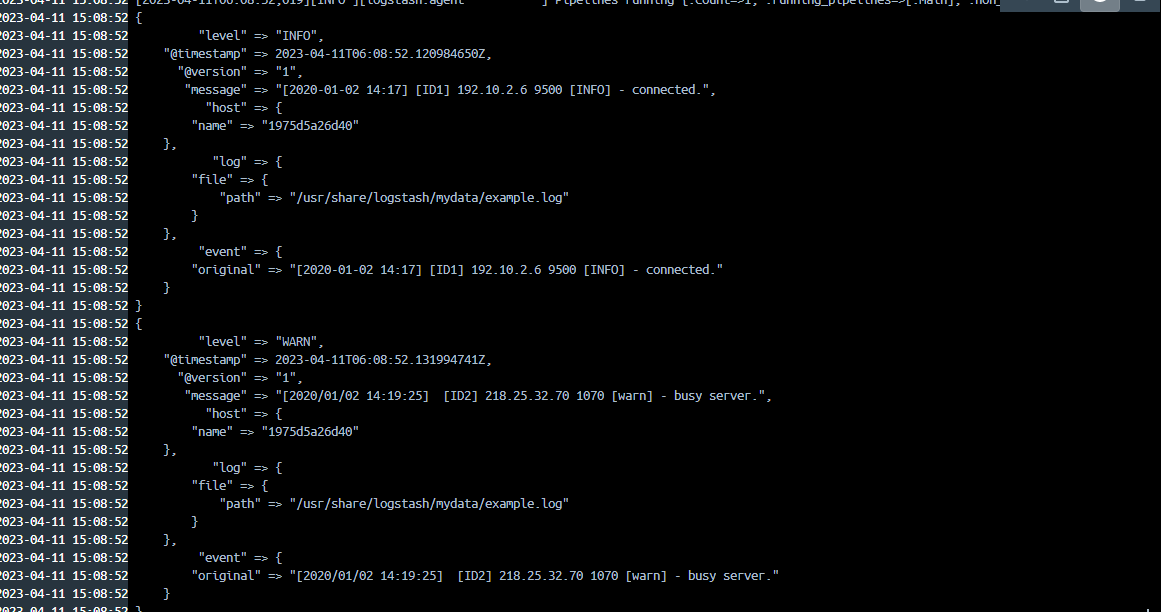
level 필드의 데이터가 warn 에서 WARN으로 변경되었습니다. mutate 플러그인의 owercase라는 옵션은 반대로 대문자를 소문자로 변경합니다.
날짜/시간 문자열 분석
이벤트가 발생함에 따라 생성되는 로그는 포맷이 통일되어 있지 않다는 문제가 있습니다. ISO08610 같은 표준 표기법이 있지만 강제적은 규약은 없습니다. 이렇게 다양한 포맷을 date 플러그인을 이용하여 기본 날짜/시간 포맷으로 인덱싱할 수 있습니다.
logstash.conf
...
filter {
dissect {
mapping => { "message" => "[%{timestamp}]%{?->}[%{?id}] %{?ip} %{?port} [%{level}] - %{?msg}." }
}
mutate {
strip => "timestamp
}
date {
match => [ "timestamp", "YYYY-MM-dd HH:mm", "yyyy/MM/dd HH:mm:ss" ]
target => "new_timestamp"
timezone => "UTC"
}
}
...우선 앞서 사용했던 dissect 플러그인으로 문자열을 자릅니다. timestamp 필드만 제외하고 나머지 필드는 무시합니다. 다음 mutate 플러그인의 strip 옵션은 선택한 필드의 양옆에 공백이 있을 경우 제거하는데, dissect에 의해 만들어진 timestamp 필드 좌우에 공백이 있다면 제거됩니다. date 플러그인은 데이터를 ISO08601 타입으로 일괄적으로 변경합니다. match 옵션의 첫번째 값은 매칭할 필드명이고 이후 값들은 매칭할 날짜/시간 포맷입니다. 여기서는 timstamp 필드 중에서 "YYYY-MM-dd HH:mm", "yyyy/MM/dd HH:mm:ss" 포맷인 경우 매칭됩니다. target 은 match에 의해 매칭된 필드가 저장될 새로운 필드를 의미하고, timezone은 원본 문자열에 타임존 정보가 포함되어 있지 않을 때 어떤 타임존으로 분석할지 설정합니다.

new_timestamp라는 새로운 필드가 생성되었고, 시간 포맷이 달랐던 두 데이터가 ISO8601 타입의 포맷으로 통일되었습니다.
조건문
필터는 기본적으로 모든 이벤트에 적용됩니다. 로그스태시는 일반적인 프로그래밍 언어와 동일한 형태로 if, else if, else 조건을 제공하며, 이를 이용해 이벤트마다 적절한 필터를 적용할 수 있습니다.
logstash.conf
...
filter {
dissect {
mapping => { "message" => "[%{timestamp}]%{?->}[%{id}] %{ip} %{+ip} [%{?level}] - %{}." }
}
if [level] == "INFO" {
drop {}
}
else if [level] == "warn" {
mutate {
remove_field => [ "ip", "port", "timestamp", "level"]
}
}
}
...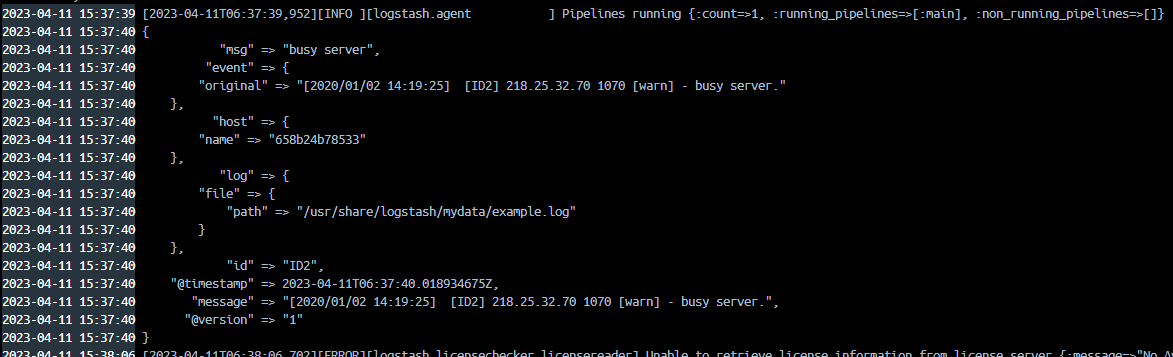
조건문에 의해 level 이 "INFO"였던 첫번째 로그는 출력되지 않았습니다. 그리고 level이 "warn"이었던 두번째 로그는 mutate 플러그인에 의해 ip, port, timestamp, level 필드가 사라진 것을 확인할 수 있습니다.
'개발 > ELK' 카테고리의 다른 글
| [Elasticsearch] 클러스터 구축하기 - 1 (0) | 2023.08.19 |
|---|---|
| Elasticsearch 기본 (0) | 2023.05.17 |
| [Elasticsearch] 집계 쿼리 (0) | 2023.04.10 |
| [Elasticsearch] 검색 쿼리 (1) | 2023.04.07 |
| [Elasticsearch] 벌크 데이터 bulk API (0) | 2023.03.27 |




댓글